
I have a Docker container running on a virtual machine and I'm trying to upload a file to S3 (or Google Cloud Storage, both with the same result) from inside it. While there are no problems for small files (<1MB), with larger ones the connection is reset by the remote end in the middle of the transfer and a Broken Pipe or Connection reset error is raised by the application. If I execute exactly the same command from the virtual machine itself, everything works fine. The problem appears only when the command is run from inside the container. (Docker uses iptables to forward traffic, maybe that's the culprit). I started measuring the traffic on the "docker0" interface from the virtual machine, and I noticed that the connection is reset shortly after each time that a "TCP Previous segment not captured" message occurs. The capture is available at http://www.cloudshark.org/captures/77be48e86fc1 can somebody explain me why this happens and what can I do to solve this situation? asked 10 Jan '14, 08:11 GaretJax edited 12 Jan '14, 03:27 Kurt Knochner ♦ |
One Answer:
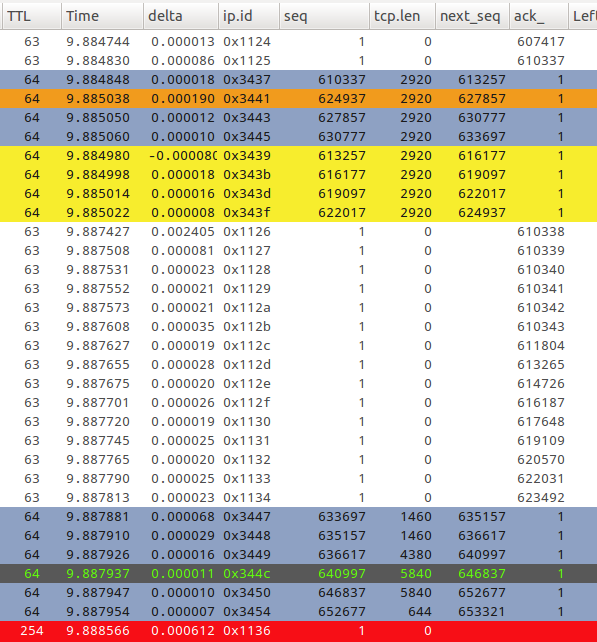
Packets 377-380 are written out of order into the pcap file. The timestamps of those are earlier than 374-376, which can only mean they were 'timestamped' correctly. If the trace was taken in the VM (virtualbox) tracing docker0 interface then it is probably the VM that is also forwarding them out_of_order to then next hop. The receiving TCP (one hop away - so probably not S3 but some proxy software in your host OS) is responding by acking 1-byte segments 610338,610339,610340,610341,610342,610343 with a RTT of 2ms. Soon after that the RST arrives with a TTL of 254, so again must be coming from the TCP layer 1 hop away (TCP in your VM host system?) I'd suggest you continue to analyze there ...
answered 12 Jan '14, 04:33 mrEEde We hit a similar issue with running an HTTP server in a container and reported it as a Docker issue a while back (3089). Did you find a solution to your flavor of the problem? Any information you can share would be much appreciated. (Tried to add this as a comment, but the site keeps marking it as spam, no matter what I do.) (06 Sep '14, 06:26) parente I'm sorry @parente, I gave up, moved the registry from google cloud to brightbox and everything started working correctly (note that storage is still on S3). (19 Sep '14, 09:46) GaretJax |
There is no trace at that URL.
Please try again now