
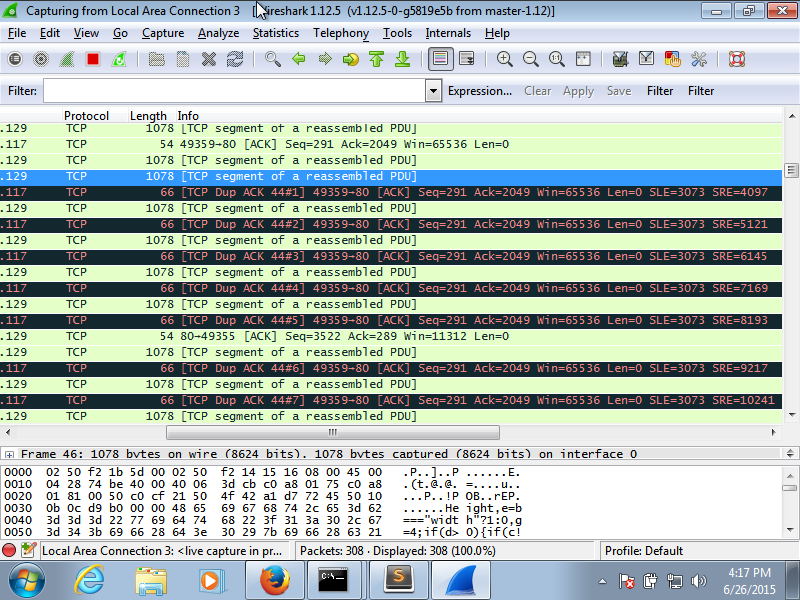
Hi there, I'm running wireshark to try and sort out what is going wrong with my tcp connections to my server. It runs fine for the first while and loads a few small files but for a big file I think it eventually drops a packet. Which should be fine except the SRE value of the DupAck keeps increasing as the server sends more packets, It finally triggers a fast retransmit, after DupAck #12 and he sends back the initial missed packet, bytes 3073 to 4097, but by then its too late as the DupAck already wants SLE 3073 to SRE 15361 so he just keeps DupAck-ing and eventually the server seems to just stop trying, there's a lot of keep-alive and retransmission attempts. Here's a picture of the suspected packet loss point. Any ideas? I've been working on this connection for days and have no idea what's going wrong. Thanks! asked 26 Jun '15, 12:25 Graeme |
One Answer:
You were losing a segment early ( the 3rd segment tcp.seq==2049 tcp.nxtseq==3073) in a batch of segments coming in from your server. As your client offered a 64K window_size the server was sending 15 segments in a row 1024 bytes each immediately after your initial GET request. So seeing the SRE value increasing with the SLE value staying at 3073 is normal. The server should eventually retransmit the lost segment tcp.seq==2049 tcp.nxtseq==3073 If it doesn't do this as you indicated - seeing keepalive packets it might not be getting your ACKs at all ... The IP addresses indicate the server is in your local network, however the server sending 1024 MSS segments indicates that he saw your MSS offering as 1024. What is the MSS value offered in the client's SYN packet? If you don't see 1460 then check your MTU size. Reading through this again, you say "after DupAck #12 and he sends back the initial missed packet, bytes 3073 to 4097," This segment was never lost, it arrived at the client. If you still see it re-transmitted it the server did/could not read the SLE-SRE information correctly/at all and it might be due to Regards Matthias The latest trace shows SACK no longer being used.
The circumvention will be to slow down the sender by a combination of
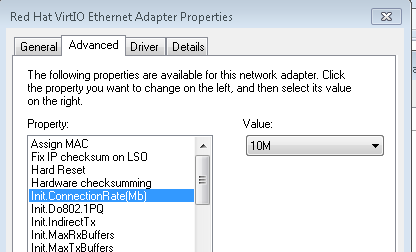
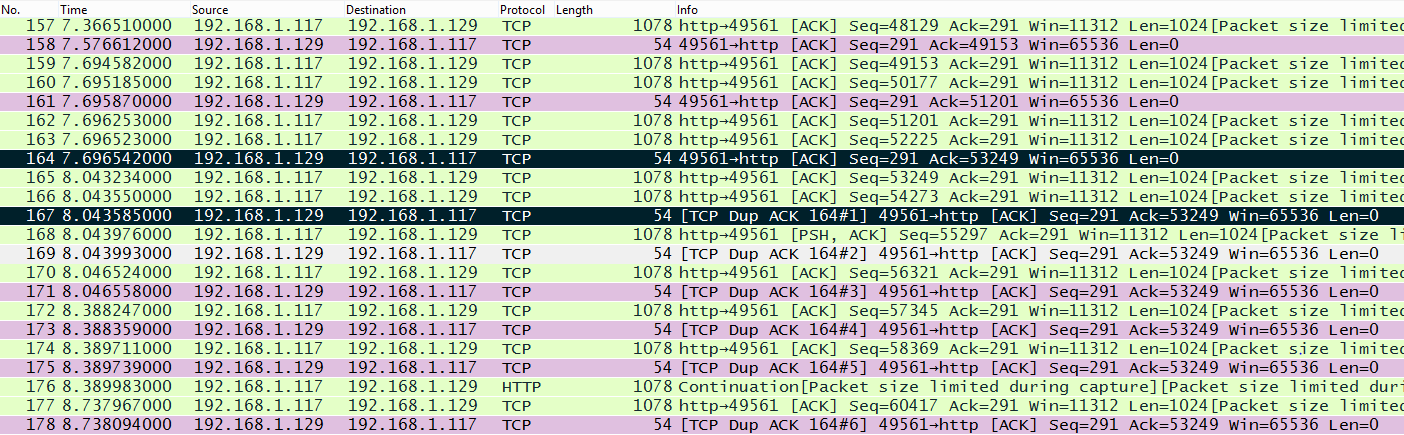
For windows to reduce the windowsize you can disable auto-tuning to disable window-scaling . Open elevated command prompt with administrator’s privileges. To reduce the rwin to less than 64k you need to change the speed of your adapter to 10M In firefox multiple requests can be sent before any responses are received. answered 27 Jun '15, 09:27 mrEEde edited 03 Jul '15, 07:31 Hi Matthias, Thank you for your answers. Here is a link to the captured ip/tcp headers: https://drive.google.com/file/d/0BynRhiTlgNo9Nm1fc01sd2tLN00/view?usp=sharing I'm trying to communicate over a slip connection so I set the MTU size, on both sides of the connection, to that becuase it was the smallest, power of two plus 40 size that my adapter would allow. Should I make it bigger? In terms of the SACK is it likely to be my adapter that's not liking that or the server side of things? I'll try turning off the SACK for my adapter and see how that goes. (29 Jun '15, 06:04) Graeme Also I'm not sure how to turn SACK off, I tried adding the SackOpts registry value as all googling has suggested but it seems to have no effect (29 Jun '15, 08:33) Graeme The packets are cut off after 54 bytes so they don't contain the TCP SACK options. We would need at least 66 bytes to see SLE_SRE ... (29 Jun '15, 10:46) mrEEde Sorry! yes that was foolish of me, here's more info https://drive.google.com/file/d/0BynRhiTlgNo9TENfODROMXVXaGc/view?usp=sharing Though this capture is after I've attempted to shutoff the SACK so might not have all the info, though still has the same initial problem that the conversation breaks down (29 Jun '15, 11:55) Graeme @mrEEde (here is the chance to earn extra points) I assume we are tracing at the IP-Address 192.168.1.129. So for this I can´t explain me with the root-cause of "WindowSizing" why the host 1.129 inititiates the DUP-ACK row. Because I can see packet 165 and 166 correctly arriving at the capture point (still assuming capture point is stack 1.129) in the trace. And at this moment (FRAME 167) I can´t see a lot of bytes in flight. So I personal think that something goes wrong at the host 1.129 at this moment FRAME 167. Please correct me if I am wrong. And as I told I will honor it. (29 Jun '15, 15:05) Christian_R The trace was taken at the windows client as Statistics Comments Summary shows. The 'root cause' is a high number lost packets and retransmissions, obviously because we are receiving (and sending btw) more packets than the networking infrastructure ( a serial line in this case ?) can handle. The offered window_size of 65536 is already too high to get a smooth transmission. Reducing the window_size is one workaround to slow the sender down, the other one is reducing the number of concurrent sessions. Regards Matthias (29 Jun '15, 22:19) mrEEde Don't know why my prev comment is not shown here. So I repeat it: As I promised I voted up your. Because I think you are right. (29 Jun '15, 23:38) Christian_R Matthias, Thanks again for you help. Is there any way you know to set the max window size? I've shut off the scaling and heuristics but it still seems to have a window size of 65500. I tried setting registry values for TcpWindowSize and and max window size but they had no effect (I'm working on windows 7). Here are my latest captures (from both sides) with a smaller mtu and the limited connection requests (the setting is something like pipelining connections in Firefox now btw) Client side: https://drive.google.com/file/d/0BynRhiTlgNo9dWN0YkFIYmVsWVU/view?usp=sharing Server side: https://drive.google.com/file/d/0BynRhiTlgNo9M0hUUmhRRDRReUE/view?usp=sharing Yes the network infrastructure is my program (to do the SLIP encapsulation) that is using a serial line. (01 Jul '15, 10:41) Graeme I found some bugs that were causing checksum errors, Causeing the seemingly random package dropping, so things are working much much better now. Still interested if anyone knows how to set the rwin size though, haven't found a working solution for that anywhere (02 Jul '15, 07:42) Graeme Maybe this will help: http://smallvoid.com/article/winnt-winsock-buffer.html ... A small AFD-Receive-Window will constantly be saturating the application receiving data (And blocking the remote sender). Don't know if it is still valid with win7 though. I believe FF sets the SO_RCVBUF socket option - which will take precedence :-( (02 Jul '15, 10:04) mrEEde 1 The windows networking stack selects RWIN based on the link media type, so if your Windows machine thinks it's connected to a gigabit switch, Windows will set RWIN at 64k at least. If you pretend to be connected to a 10Mbit hub, Windows will set RWIN at around 16k. I also tried forcing my Windows 7 machine's network driver to use 10Mbit, which apparently reduced the RWIN to about 16k. Also, you now have TCP timestamps enabled which steals you another 12 bytes in every segment... So I suggest you issue netsh int tcp set global timestamps=disabled netsh int tcp set global autotuning=disabled netsh int tcp show global and reduce the speed of your adapter to 10M . Regards Matthias (03 Jul '15, 00:06) mrEEde showing 5 of 11 show 6 more comments |
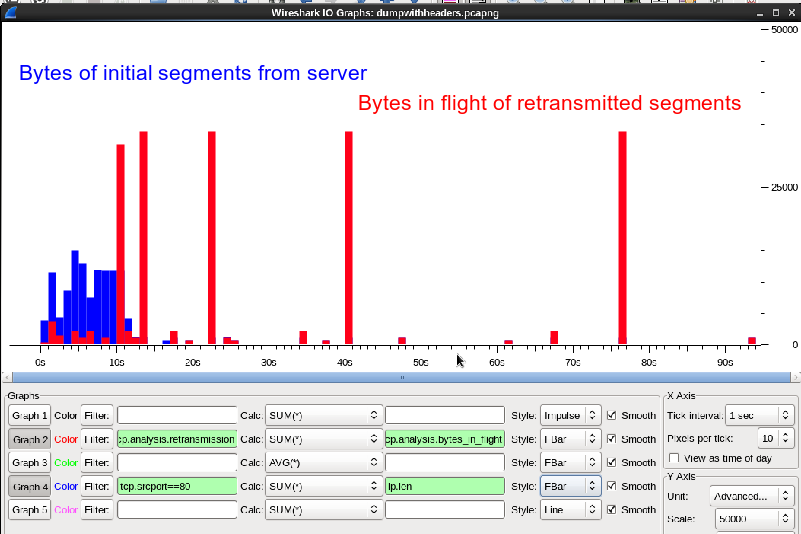
Can you please upload a small capture file somewhere (google drive, dropbox, cloudshark.org) and post the link here?
Because I can´t see the sequence number at the picture.
The SLE and SRE parameters are part of the SACK and D-SACK techniques and are described here: RFC 2018 and RFC 2883
And maybe this hint could help you too: Go to Edit > Preferences > Protocols > TCP and uncheck "Allow subdissector to reassemble TCP streams."
"It finally triggers a fast retransmit, after DupAck #12" ... so this seems to be the the view at the receiver side as the sender should retransmit after having seen the 3rd dupAck.
Of course it takes half of the RTT for the sender to see this 3rd dupACK and in the meantime there were 9 additional segments arriving "out_of_order" triggering the additional dupACKs - "as the DupAck already wants SLE 3073 to SRE 15361"
the SLE-SRE indicate which bytes have been received after the gap occured.
As Christian_R indicated we would need to see the capture to really be able to understand what is going on. editcap -s 90 can be used to stripp off the data - if it contains confidential data ...
Regards Matthias