
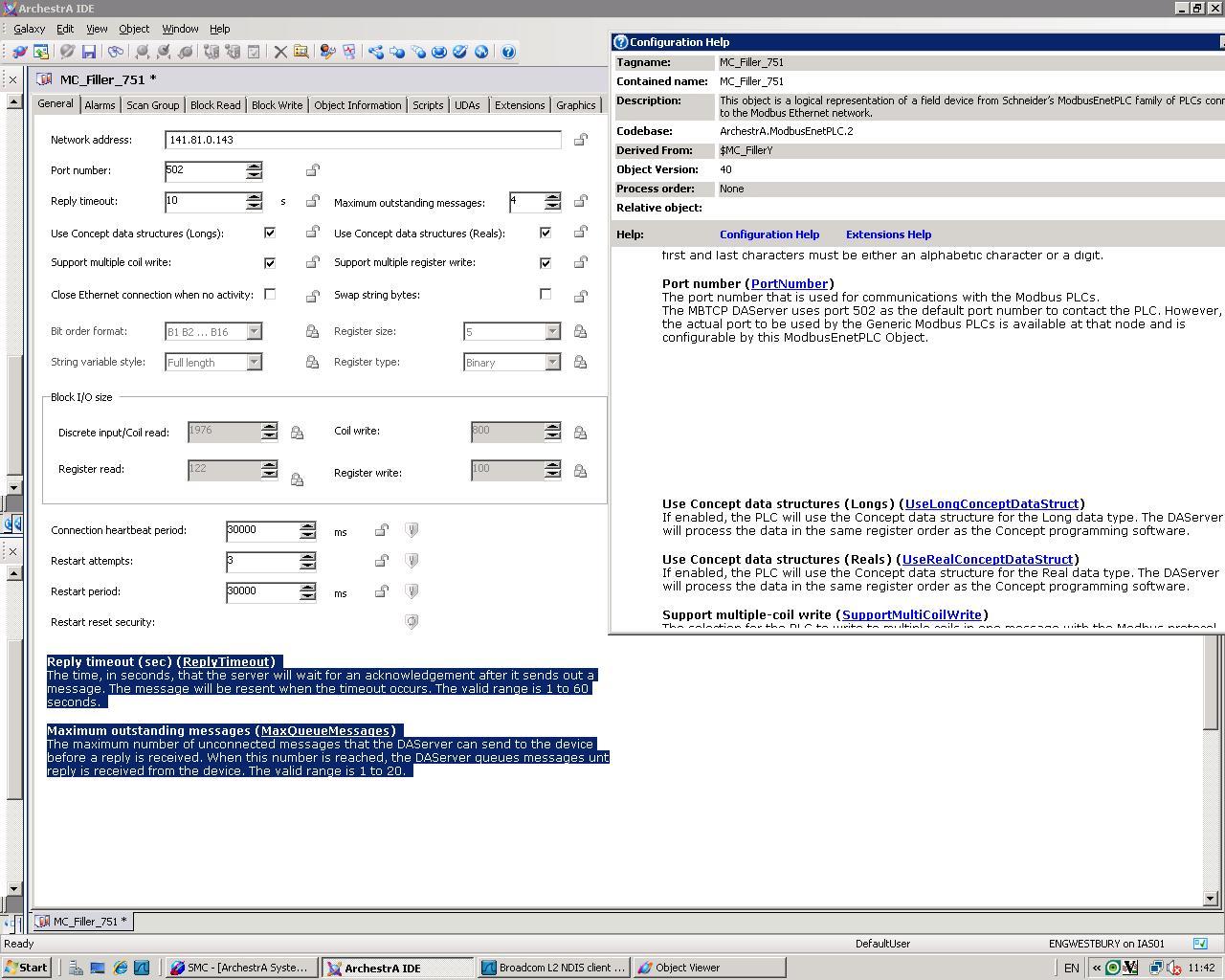
Hello, Here is my problem. In an industrial automation environment we have one Modbus Master system and serveral Modbus slave's (13 x PLC's/PC devices). Modbus communication is working, but frequently (twice per hour) we lose the connection to one of the devices (everytime a different device). This takes a couple of seconds (10-20 sec) and then the communication starts again. We can see that the frequency of missing the connection is related to the number of slaves active on the network. When we have less slaves on the network it still happens but less frequent. In our Modbus Master system there is no good log available to see what is happening. I used Wireshark to capture the datatrafic between the master and the slaves. I've got a situation captured, but to be honest i really don't know what i am looking at in Wireshark. Hopefully someone can explain to me what the Wireshark log can tell me. Thanks, Niels Hereby a link to the file on cloudshark: Problem is between 141.81.0.10 and 141.81.0.46 on time: 03 min, 46 sec until 04 min, 06 sec Hopefully this will help to find my problem???? Thanks Screenshot of Configuration in Master System (Wonderware AcherstrA). The Modbus devices are Elau PLC controllers. Also we communicate with an Xray machine wich has a dedicated PC based controller. Thanks to everyone for cooperative thinking and helping.
asked 13 Nov '12, 04:21 Niels edited 15 Nov '12, 13:44 Kurt Knochner ♦ |
4 Answers:
@Bill Meier might be on to something here. In the first capture, if you filter by the rtu address (ip.addr == 141.81.0.46) and look at the frames preceding the connection close, i.e. 29986 onwards, you can see a sequence of Read Input Register requests. Looking at the Modbus/TCP headers you can see the "Transaction Identifier" that allows the master to match up responses to queries and have multiple queries in flight. Standard Modbus doesn't have this as it's a strict request/response protocol, but the TCP variant does. So the query in frame 29986 has TI's 28532-28534. The response (30004) has the responses to those TI's. The next query (30006) has TI's 28535 & 6. The next response (30067) has the responses to those TI's. The next query (30069) has TI's 28537-28540. The next response (30107) only has TI's 28537 & 8 so TI 28539 & 40 are still outstanding (in flight). The master then sends a query (30109) with TI 28541 and then another query (30126) with TI 28542-28544. Note that the latter two are actually coil writes so I'm speculating that the master pushed the writes out immediately (as we all like output ops to happen quickly) so now we have TI's 25839-25844 all in-flight. The rtu responds (30149) with TI 25839 & 40, so TI's 25841-44 are still in-flight. Now we have the near 10 second gap until the rtu sends the tcp keep-alive (36817) and very quickly after that the master closes the connection. I think that the number of TI's in-flight (4) cause the master to not send any more queries until the rtu responds, and as this doesn't happen in 10 seconds or so (a master timeout?) the master recycles the connection. I would further speculate that if the master has a write request, it may exceed the "normal" number of in-flight requests. You need to check the permitted number of in-flight requests for the rtu, and (if possible) configure the master to not exceed that. Out of interest can you name the master software and the rtu vendor? I also note that the master is not coalescing reads, i.e. it's sending out "overlapping" read requests and thus it's not making the most efficient use of bandwidth, e.g. frame 29869 requests 70 registers from starting index 201 (201-270), and then the next query (29916) in TI 28528 requests 1 register from index 206. This new read is entirely contained in the previous query. answered 14 Nov '12, 03:25 grahamb ♦ Hello Grahamb, Very impressive!!!! I've looked at the settings and made a screenshot of the configuration i can make in our system (Wonderware ArchestrA). The two settings you mentioned are there (see original edited problem) What do you suggest I should do with those settings. (increase them to the max???). Thanks for all your time and effort.... Niels (14 Nov '12, 03:58) Niels 1 Competitors product, I couldn't possibly assist :-) However as I have a Wireshark hat on at the moment not the day job, try reducing the number of outstanding messages. This means the rtu doesn't have to buffer as many responses. Increasing it just means that the master can send even more requests before giving up on the rtu, and the rtu has to buffer all those requests and responses. (14 Nov '12, 04:30) grahamb ♦ 1 Analyzing further (with a little help from perl):
For example: filter on 'ip.addr eq 141.81.0.66' and then look at frames 12481 and 12504. You will see that 5 'Read Input Registers' queries and 1 'Read Discrete Inputs' query are queued before there is a response. There are a fair number of similar sequences in the capture. In all but one of these cases there is no failure. (See below). (Continued below) (14 Nov '12, 10:17) Bill Meier ♦♦ (Cont'd) (Note: I've no experience with the Modbus protocol or the vendor software, so I'm just taking the parameter to mean what it sounds like).
Another queueing case in the capture was similar but did not fail: 3 "Read Input Registers" 2 "Write Multiple Coils" 1 "Read Input Registers" (Continued_ (14 Nov '12, 10:26) Bill Meier ♦♦ (Cont'd) So: It smells to me like the vendor(s) may have some timing (and maybe other) issues with their software. If reducing the "maximum ..." parameter reduces but does not completely do away with the issue, I certainly wouldn't be surprised. IMHO, any timing issues need to be fixed not minimized. The phrase "communicate with an Xray machine" doesn't make me comfortable. I suggest discussing the issue and this capture with the vendor(s) (if you haven't already). As I said, I've no experience with the Modbus protocol or the vendors so all of the above is just my opinion ! (14 Nov '12, 10:34) Bill Meier ♦♦ P.S. adding columns for mbtcp.trans_id and modbus.func_code helps to see what's happening when looking at the capture. This can be done by separately right-clicking each of the two fields in the details pane and doing 'Apply as column' (14 Nov '12, 10:41) Bill Meier ♦♦ 1 @Bill Meier I don't think it's a timing problem, as the master correctly waits the configured 10 seconds for a response before recycling the connection. The master does exceed the configured number of messages outstanding though, and depending on how the rtu reacts to that is the cause of the problem. In the area I looked at, the rtu just fails to respond, so what is it doing? At best it's just running normally but the comms stack is a little behind and will catch up eventually. At worst the rtu may be undergoing a reset which is not likely to have a good effect on the equipment it's controlling. Hopefully reducing the limit on the number of outstanding messages means that the master will reduce the actual outstanding messages, even if it does exceed the limit a little and the rtu will cope better. Personally I'd set it to 1. For Modbus/TCP the ability to have outstanding messages doesn't add much, as the system is still limited by the response rate of the rtu to those messages, and many rtu's don't have the buffer capacity to hold the outstanding requests. (15 Nov '12, 01:54) grahamb ♦ Hello Everybody, Just an update, I've put the Maximum number of outstanding messages at this moment for all my 13 devices to 1!!! So far so good. I am monitoring constantly the status of the Modbus communication (not via wireshark), but via my application software, and since this morning i did't have any communication problems. I will let it run a couple of days like this and then will post another update. And Once more, Thanks for all your time, thoughts and suggestions. Niels (15 Nov '12, 02:12) Niels @grahamb "I don't think it's a timing problem, as the master correctly waits the configured 10 seconds for a response before recycling the connection. ..." Sounds reasonable .... (15 Nov '12, 06:59) Bill Meier ♦♦ Update: Problem Solved: I have changed the maximum outstanding messages to 1. This is active now in the factory for several days and no communication error has occured since then!!! Many thanks to Grahamb who solved the mystery.... Regards, Niels (20 Nov '12, 00:08) Niels Glad to hear the issue has been resolved. Can you accept the answer that solved your issue by clicking the checkmark icon next to the answer? This highlights the best answer for the benefit of other users. (20 Nov '12, 01:26) grahamb ♦ showing 5 of 11 show 6 more comments |
When referring to frames of interest it's best to use frame numbers rather than times that can be affected by the time-zone of the viewer. I filtered by the ip address of the target rtu (ip.addr == 148.81.0.46) and can see that at frame 36817 the rtu sent a tcp keep-alive 9 seconds after the last communication from the master (30207), and the master ACK'd that then almost immediately after closed the connection and opened it again. Again after the ACK from the master indicating the connection was open (37003) there is a 9 second delay before the rtu sends a TCP Keep-alive (43200) and the master sends back the ack (43201). Half a second later the master starts sending requests. So what happened around this period of interruption? Clearing the display filter to see all packets shows that the master is quite happily exchanging packets with other Modbus/TCP rtu's, and plenty of other traffic, e.g.CIP, some SQL server and some TPKT. There doesn't seem to be any issue with the network, may be the master is just too busy? answered 13 Nov '12, 07:23 grahamb ♦ Thanks Grahamb, I've captured yesterday another link down. This one have some red lines in the log of wireshark. Maybe this tells you more??? Link = https://www.cloudshark.org/captures/3bfef9452c76 Rtu device is now: 141.81.0.86 and something goes wrong between frame 1014 and frame 9975 Thanks in advance, Regards Niels (13 Nov '12, 08:07) Niels |
I also spent a little time doing an analysis ... :) As noted in the previous answers:
For the first capture I spent a little time looking at the traffic on the connection which failed after a hiccup. The one thing I noticed is that there was a long sequence of repeated "READ INPUT REGISTER" queries just before the hiccup. In fact, there were 24 successive queries and this is the largest number of successive of "READ INPUT REGISTER" queries on a connection in the whole capture. Is this meaningful ? I've no idea. To see if there's any pattern related to the failures which can be seen in the captures, additional captures covering the time period of a failure would be needed. answered 13 Nov '12, 14:47 Bill Meier ♦♦ |
The screen shot is pretty hard to read, especially with these migraine-inducing color rules. As far as I can tell you have some inactivity in there, leading to TCP keep alives (all normal), and then a normal session teardown using FIN-ACK-FIN-ACK. Then a new connection is started (SYN). As far as I can tell from the screen shot there is no critical situation there - looks like inactivity between server and slave leading to a "we don't need this session anymore"-behaviour. Try filtering for "tcp.analysis.flags" and see if there's something bad happening - if you find a connection that zero window messages, or has long delays (see the time column) or reset packets (filter for "tcp.flags.reset==1") you might be onto something, but it is often hard to tell with the Modbus stuff. answered 13 Nov '12, 04:42 Jasper ♦♦ Hello Jasper, I've uploaded the file to cloudshark. Maybe you can have a look?? Thanks, Niels (13 Nov '12, 06:40) Niels Sure... but I'd need the link ;-) (13 Nov '12, 07:14) Jasper ♦♦ Jasper, Link is in my original posted message. (13 Nov '12, 07:32) Niels Jasper, this link (capture of link down yesterday) has a warning log with windows = 0 at frame 3676. https://www.cloudshark.org/captures/3bfef9452c76 hopefully this makes sense to you??? Thanks, Niels (13 Nov '12, 08:13) Niels The Zero Window in frame 3676 is not a problem in itself, since it is a Reset packet, and these always have a window of 0. In that trace we can see that the IP addresses 141.81.0.10 and 141.81.0.86 have a little trouble finishing their connection (Stream Index 1). There are a couple of retransmissions from 141.81.0.10 followed by a FIN which is again retransmitted, and finally the FIN from 141.81.0.86, after which no more packets should arrive, but 141.81.0.86 does send a packet in frame 3674. This leads to an "angry" RST from 141.81.0.10. (13 Nov '12, 08:54) Jasper ♦♦ |
Can you add your capture to CloudShark and post a link back to here? Only do this if the data isn't sensitive. This is required as we can't really diagnose an issue via a screen capture.
Hello Grahamb,
Link is added. Would appriciate if you can have a look!
Niels