
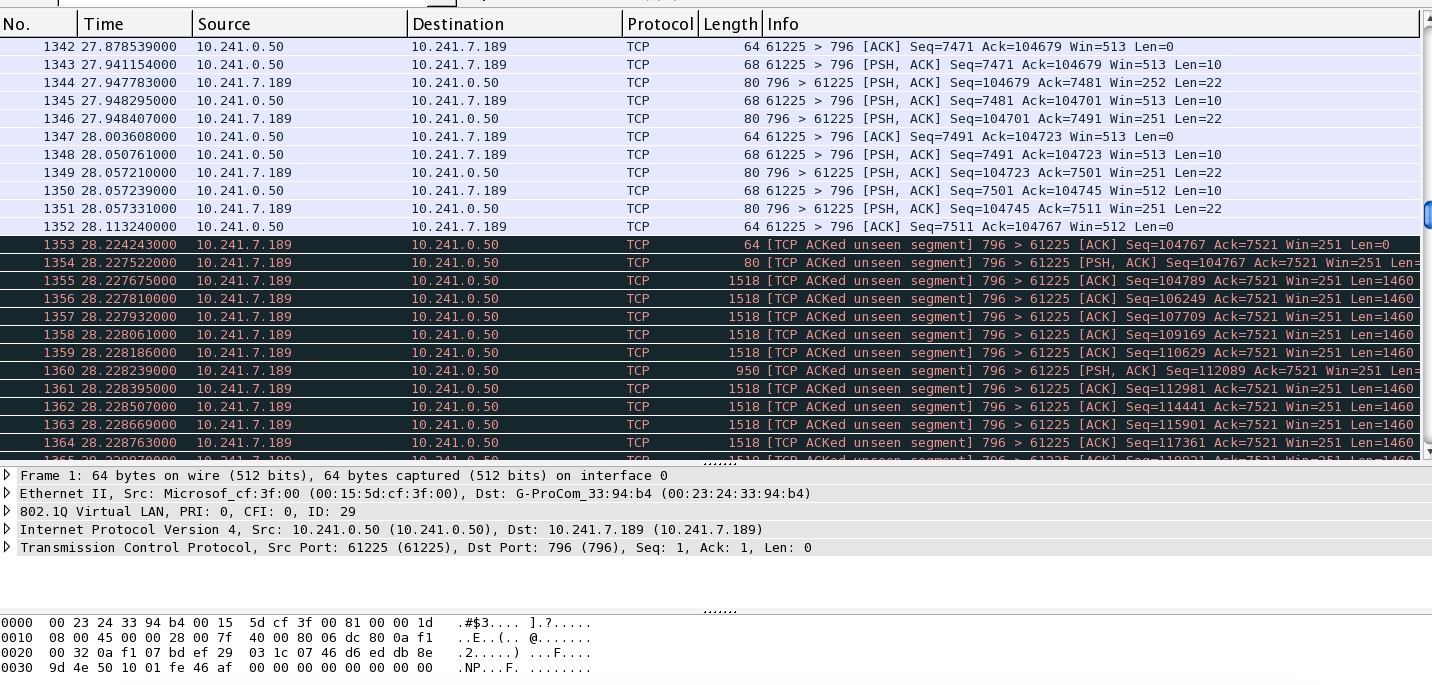
Hoping someone can provide some expert analysis explaining to me why I'm seeing this odd behaviour with my network switches. I have a server and client conversation happening across 1GB inter-switch link. Server and Client each have a 1GB connection to its local switch. I have a wireless controller connected to the same switch as the server and multiple Access points connected to the same switch as the client. For some reason, shortly after the client/server application starts, the conversation seems to use up all available bandwidth across the 1GB inter-switch link. As a result, the Access Points are not able to contact the controller and they reboot (as by design). When we manually forced the client to a 100MB connection and ran the application, the Access Points maintained connectivity and never rebooted. I have a very large packet capture taken from mirroring the client side inter-switch interface. I'll happily share the packet capture but can't yet see where to do that. Instead, for now, I'll share this screen capture. I suspect the problem begins at 1353 but I don't know what to make of it. Server is 10.241.0.50, client is 10.241.7.189
I would love to know from the experts what sort of filters you create/use in order to determine the cause. *Update: Here is the link to a filtered packet capture. link text asked 13 Jan '16, 08:03 MisterFalcon edited 13 Jan '16, 08:24 |
One Answer:
If you take your filtered capture (the one you've posted), use So I'd guess that the exhaustion of the inter-switch link comes from something else than a single tcp transmission, and that you'll have to look at the capture of the mirrored client's traffic to see what else the client is sending so heavily that it can exhaust the 1 Gbit/s bandwidth. It is enough to take such complete (i.e. not filtered and taken in promiscuous mode) capture with the speed of the switch port connecting the client machine forced to 100 Mbit/s, and it is enough to use (or post here) just a couple of seconds (5?) of that capture. But you may find out that the source of the 1 Gbit/s traffic between the two machines is e.g. another tcp session than the one you've filtered; nothing prevents the two machines from using the full bandwidth of their respective Ethernet ports if they have enough to say and if the CPU can feed the network adapters with data fast enough. So if you cannot provide more bandwidth at inter-switch links than at "tributary" ports, you may have to use traffic shaping or VLAN prioritization at the switches. Setting the client port speed to 100 Mbit/s is a rudimentary way of doing that. answered 13 Jan '16, 11:26 sindy edited 13 Jan '16, 12:41 showing 5 of 24 show 19 more comments |
Thank you sindy! That is incredibly helpful. As you can likely tell, I'm new here! I have also shared the original packet capture in its entirety but as mentioned it's large. I will attempt to get other more recent capture shortly. If there's any chance you can provide further insight it would be most appreciated.
link text
I've also broken the original capture up into smaller files, but the total of the smaller files does not comprise the entire capture. Perhaps there is something in there that points to the problem? There are multiple clients to be observed in the capture files, any host with a 10.241.7.x can be considered a client using the application. link text
@MisterFalcon
Your "answer" has been converted to a comment as that's how this site works. Please read the FAQ for more information.
Thanks grahamb, sorry, as mentioned, I'm new here. Ive just just uploaded another file to the folder which was captured today. The IP Addresses have changed as the capture was performed on a different LAN, yet the problem remains the same. The newest capture is named Wmnt-FiveClients_00029_20160114123551. It was taken directly from the server this time. I had five clients running the application. Server IP = 10.243.208.50, Client IPs = 10.243.215.132,10.243.215.131,10.243.215.136,10.243.208.130,10.243.208.129. I'm at a loss to explain what's happening to the network and hope someone can help. If it's not the application using up all the available bandwidth as as sindy mentioned, then what is going wrong? Hoping someone is willing to take a look! Thank you.
@MisterFalcon, it doesn't seem logical to me to say "sorry" and do the same what you have just apologized for once again :-)
You've asked a Question. You are free to post an Answer, but should do so only if it answers the Question (which is possible and does happen sometimes, if people find the answer themselves before anyone else answers, and spend the effort to help others having the same question). Otherwise, all your updates should be comments.
To the subject: so we take the first capture, CompleteCapturePart1, and see that its 100 k packets span some 30 seconds. The second one looks more interesting - the same 100 k packets came within less than 3 seconds. Closing the Part1, looking at Part2.
Statistics -> I/O Graphwith no display filter applied (i.e. all packets are taken into account) shows total throughput about 9 Mbit/s, not really impressive as compared to your claim that 1 Gbit/s (100 times more) are exhausted.So closing both and looking at the fresh one, give me a couple of moments...
...and in this newest capture, almost nothing happens except last second where the throughput is about 90 Mbits/s, so nothing to be found either.
I can see some duplicate TCP ACK in some of your captures, and lost segments in others, so the network seems to have had some problem during the captures. But as the bandwidth seen from those captures doesn't seem to be exhausted, something may be wrong about the throughput of the capturing machine or about your choice of capture point.
So let's have a look at your capture setup, as capturing at the server doesn't seem to be helpful.
I imagine your setup the following way:
Server ---- N:switch_A:M ----- S:switch_B:T ---- Clientthe Server is connected to 1 Gbit/s port N of switch_A
the Client is connected to 1 Gbit/s port T of switch_B
the two switches are interconnected using 1 Gbit/s ports M of switch_A and S of switch_B.
If this is true, and you claim that as soon as you connect the Client, the APs connected to switch_B lose connection to the controller connected to switch_A (or vice versa), to learn something useful, you have to set up a free 1 Gbit/s port on either switch_A or switch_B into monitoring (SPAN) mode and let it monitor just one direction of port M or S, depending on the switch where you do that. You have to connect the machine running Wireshark (or, better, just dumpcap which doesn't waste CPU power to analyse the traffic and just dumps it to a file) to this monitoring port and capture while the state of overload exists. Capturing for about two seconds should be enough as it should yield over 200 Mbytes of data. Then you have to change the monitored direction and capture for another two seconds, and post both files (split into parts if necessary).
Ideally, you would have two 1 Gbit/s ports on the capturing machine and would be able to set two monitoring ports (one per switch should be OK too) and capture both directions simultaneously (but each direction would use its own monitoring port/capturing network card pair).
So if you would use two monitoring ports at switch_A, one of them would monitor Tx direction of port M, and the other one would monitor Rx direction of port M; if you would use one monitoring port on each switch, one of them would monitor the Rx direction of port M and the other one would monitor also Rx direction of port S.
So what can be seen is, that the packet gap is sometimes very low (around 1 microsec) So for more further analysis I would have a look at the switch counters(are there packet drops). And also I would imagine if the APs-communication uses the same Ports like these TCP connection.
In other words is there a need for the APs to get a packet between the packets of the TCP-Session. If yes... then maybe packet loss could occur. But this all is more or less just guessed, because your infrastructure is not 100% clear to me.
I now see my error in posting comments. Regrets... sindy is correct with the topology written above. I have captured packets as requested. The link to those captures can be found here https://drive.google.com/a/gapps.yrdsb.ca/folderview?id=0BwEJI4bTrn1FaVNidVFuRElOTlk&usp=sharing Curiously when connected to switch_B performing an RX capture wireshark crashed. I resumed the capture after the crash but don't know if it contains much useful information. The issue is not that all the bandwidth is being used up as I originally thought, I just don't know what is causing my AP's and perhaps all other network traffic to freeze. All help is appreciated. Thank you.
Wireshark may have crashed as the traffic was too high for it to handle. What hardware do you use to capture?
In any case, please use dumpcap instead of Wireshark, see this article for details and reasons.
And, while waiting for access to the files, have you noticed @Christian_R's recommendation to have a look at the switch statistics for dropped packets at the inter-switch link (at both switches of course)?
As you could use monitoring mode, your switches seem to be manageable, so packet statistics should be available on them. It also means that the switches could be capable of store-and-forward mode and traffic queueing, so if @Christian_R is right that the packets collide, configuration should cure that. What is the make & model of the switches?
Thanks for that. I did notice your recommendation about dumpcap and will have to try that if I am again able to perform the same capture. I don't necessarily have adequate hardware to perform captures with, I just placed an 'standard' HP laptop with a GB adapter on each switch. The switch_A port does show some 'Dropped on No Resources' errors. There are 0 collisions/FCS errors etc. The switches are Avaya ERS 4850GTSPWR+.
The value of 0 is like I have expeted this counter.
That is the type of counters in which we should be interested.
This counter should be observed by you. It can be a sign, that the switch is overloaded by so called micro bursts.
If we really deal with micro bursts,is hard to say, due to your capture hardware. From my point of view it is as a standalone evidence not reliable enouigh. But in combination with other indications, like counters, it can become more reliable.
How much is "some" in "some 'Dropped on No Resources' errors"? Are these units of packets per second, or thousands, or more?
Because when looking at your captures,
Statistics -> Conversations -> TCPshow me things like 350 Mbits/s bursts from the server 10.243.192.50 to the client 10.243.215.218:54896 or :54897 (700 kBytes in 15 ms).As @Christian_R has pointed out, if 1514 byte (12112 bit) packets come 12 μs or less apart from each other during these bursts, there is no space left between them at 1 Gbit/s for any other packet.
Take the capture file
WMNT-SwicthB-MirrorPointS-RX_00002_20160115124834.pcap, use display filtertcp.stream eq 224and observe long bursts where frame numbers in the packet list increment by one (which means that no other packets than those belonging to that tcp stream could squeeze in) and the delta between packets is less than 12 μs while packet size is 1514 bytes.1 Gbit/s means that it takes 1 ns to send 1 bit, so 12112 bits take 12.112 μs, so the network adapter buffers and the process scheduler of your laptop come into play and deliver the received packets to Wireshark in bursts, which explains the even shorter delta between those packets. What matters is that there are no other packets in between them, not the exact timing which is obfuscated by the capabilities of the hardware and OS used to capture.
From the leaflet:
So the time has come to start using these "sophisticated QoS capabilities" :-)
Look for keywords like L3 QoS, VLAN QoS, priority queueing etc. in the switch configuration guide, as this type of traffic handling should be configurable at your switch. Your goal would be to provide the heartbeat traffic of your infrastructure with an absolute priority over the user traffic.
I'm afraid Wireshark cannot tell you more at the moment, so if you want to talk about that more, it should take place outside this site.
THANK YOU!! That helps a lot. There are all sorts of QoS settings available on these switches, I would prefer to not tweak them in our LAN environment. I have just observed that the inter-switch links show massive amounts of Jumbo Frames while the application is running and the Dropped on No Resources increments quickly. It's as though the switches are trying to combine the packets into Jumbo Frames for transport across the link but for some reason many of the packets are dropped. Will post another comment with the stats, They don't fit in the available character remaining for this post
Server Interface Stats Received Packets: 306494086 Multicasts: 57744 Broadcasts: 3517904 Total Octets: 409535963140 MTU Exceeded: 0 FCS Errors: 0 Undersized Packets: 0 Oversized Packets: 0 Filtered Packets: 44 Pause Frames: 10 Transmitted Packets: 113546471 Multicasts: 4501546 Broadcasts: 17075743 Total Octets: 28501841113 Collisions: 0 Single Collisions: 0 Multiple Collisions: 0 Excessive Collisions: 0 Deferred Packets: 0 Late Collisions: 0 Pause Frames: 0
Packets 64 bytes: 77720879 65-127 bytes: 18419389 128-255 bytes: 29850719 256-511 bytes: 13783494 512-1023 bytes: 2544681 1024-1518 bytes: 277721395 1519-9216 bytes(Jumbo): 0 Dropped On No Resources: 102
Inter-Switch Interface Stats Received Packets: 20117976 Multicasts: 8216 Broadcasts: 24019 Total Octets: 3816776605 MTU Exceeded: 0 FCS Errors: 0 Undersized Packets: 0 Oversized Packets: 343161 Filtered Packets: 0 Pause Frames: 0 Transmitted Packets: 45690435 Multicasts: 3861 Broadcasts: 68061 Total Octets: 64368730173 Collisions: 0 Single Collisions: 0 Multiple Collisions: 0 Excessive Collisions: 0 Deferred Packets: 0 Late Collisions: 0 Pause Frames: 0
Packets 64 bytes: 4819 65-127 bytes: 5831259 128-255 bytes: 15908445 256-511 bytes: 933428 512-1023 bytes: 710787 1024-1518 bytes: 952872 1519-9216 bytes(Jumbo): 41466803 Dropped On No Resources: 434594
I still haven´t a full picture of your network in my mind. So I could give you just some loose thoughts of mine:
Jumbo Frames needs longer to be transmitted and have a lesser number of inter frame gaps. This could cause queueing.
Probably at FastEthernet the apllication traffic arrives with larger inter frame gaps. Seems that you have to deal with congestion.
Is the whole network well configured for the Jumbo Frame support
QOS is a tuning mechanismen. And you are right, that you should know the root cause first. But then it is a legitimate solution, from my point of view.
Furthermore I can underline what @sindy has posted so far.
I've never heard about a switch merging standard-size frames into jumbo frames for transport. While adding complexity, it would actually bring almost no benefits - the 14 bytes of Ethernet headers, which you could save this way, constitute less than 1 % of the total size of a maximum sized standard frame (1514 bytes), and the sending of the jumbo frame would have to wait for arrival of the last standard frame contributing to it anyway, so no speed gain either.
So I don't think this hypothetical mechanism could be the source of jumbo frames you can see in the switch statistics. It must be some equipment in your network which sends them. Have a look at occurrence of jumbo frames at the switch ports to which servers are connected to identify that equipment.
To clog the inter-switch trunk for a couple of milliseconds, the 1514 byte packets seen in the capture were sufficient, though.
Not every network adaptor supports jumbo frames, and even if it does in hardware/firmware, their support may be switched off in the network adaptor settings. This might explain why I could not spot any frame larger than 1514 bytes in the capture file mentioned above despite the switch reporting so many of them. So before eventually capturing again, you should go to network card settings and check whether an option to enable jumbo frames is available, and if it is, enable it.
We also cannot see from the capture whether you use VLANs in your network because you use Windows machines for capturing, and Windows network drivers are famous for filtering out the VLAN headers before handing the packets over to upper layers including Wireshark.
I'm afraid that proper use of these settings is your only reliable way to make the APs stop disconnecting. As a quick workaround, you can throttle all client PCs down to 100 Mbit/s using port speed setting, but it will slow them down a lot while just mitigating the AP disconnection issue. Currently, the PCs generate bursts of traffic which are quickly over so they usually do not overlap; if you reduce the PC's speed, the same amount of data will take 10 times longer to transfer, which is likely to cause overlaps of these bursts so the inter-switch link may also get clogged now and then.
It seems the AP's use Jumbo Frames for management traffic talking back to the controller. Do you suppose I should disable the jumbo frames support on the controller? Yes we do use vlan's. The AP's and controller are on a separate vlan from the server and clients. In the captures, the controller would have an IP Address of 10.133.40.3 and any host with an address of 10.133.40.x would be an Access Point. All Switches on this LAN support Jumbo Frames and it is enabled. I could disable it if you think it might help. The server and most clients support jumbo frames but we have intentionally disabled it as not EVERY site has switches that support Jumbo frames - yet. I appreciate that configuring QoS is most definitely an elegant solution, I am hoping it is not my only solution. Thoughts? As always, thank you.
No and no. Forget about jumbo frames as potential cause of the problems.
It is just
that the picture of what's going on was not completely mirrored in your captures because the network adaptor of the HP laptop you've used for capturing was ignoring the jumbo frames if they arrived (or, also possible, I've randomly chosen a capture with no jumbo frames in it :-) )
that there was a coincidence: you've seen zero number of both jumbo frames and packet drops in one statistics window, and non-zero number of both jumbo frames and packet drops in another one, which has created a mental link between the two. But coincidence does not imply correlation.
As already said, maybe not clearly enough: if you use a 1 Gbit/s physical channel for multiple logical connections, and at least one of these logical connections is capable of sending at full 1 Gbit/s in peaks lasting for several milliseconds (means: several hundreds of packets), you simply cannot avoid packet loss if some other traffic needs to use the same physical channel at that time.
And this is exactly what you do: the server is at one switch, connected to it with a 1 Gbit/s link and capable to make use of the link bandwidth completely, and some of its clients are on another switch, and the link between the switches is also 1 Gbit/s. So:
regardless how many clients download data from a single server (server A) through the inter-switch link simultaneously, the common bottleneck is the server's network card and no packets get lost because the server does not even send them.
if some other transfer needs to pass through the inter-switch link (and in the same direction) through which server A is already sending at 1 Gbit/s, no matter to how many clients, the common bottleneck becomes the inter-switch link, and all the transfers get randomly and equally (in terms of the share of lost packets) affected by packet loss, unless you prioritize them in some way.
The transfers may however not be equal in sensitivity about the packet loss: while the TCP stack used by the client to download the contents of a web page just asks the server for retransmission (and thus increases the number of packets actually sent by the server, causing more problems!), the AP-controller communication overreacts and causes a reboot of the APs.
So to get rid of the reboots, you must ensure that the packets between the APs and their controller are not lost so heavily.
In fact it even seems to me that your switches currently give the http client-server traffic a higher priority than the AP-controller traffic, not necessarily because they are http: the criteria may be the VLAN used, the source/destination IP address, or maybe (denying my own words) the size of the packet if the switch would, for some reason not known to us, prioritize small (non-jumbo) frames over jumbo frames.
The reasons why I think so are that
the APs exhibit problems,
the TCP packets were coming so densely one after another, with no visible gaps large enough to house a non-captured frame,
Wireshark hasn't shown any lost packets by TCP sequence during the burst.
But I may have missed another file where the jumbo frames' presence has created a gap in the TCP packets.
Yes, I think explained it well. But what do you think about a larger inter switch link, perhaps a channel?
Now something about the link overbooking management. You can:
treat all frames which need to be sent through the same link (port) equally: If a frame comes while the link is free, you send it; if a frame comes while the link is occupied sending another frame, you drop it.
use simple priority queueing: for each link, you define at least two queues (of a finite length), which have a defined priority over each other. Any received frame is put at the end of one of those queues chosen up to some criteria; if there is no space left in the chosen queue, the frame is dropped. Whenever the link finishes transferring a frame, it chooses for sending the oldest frame waiting in the first non-empty queue found while searching from the highest priority one downwards. In this case, frames from lowest priority queues may never get sent.
use advanced priority queueing, which basically aims to provide at least a minimum (configured) bandwidth to even the lowest priority queue, by dynamically preferring it from time to time and tracking the bandwidth. I don't think that in your case, things should get that far that you would need to use this mode.
Logically, at some amount of the total traffic volume, queueing will stop providing satisfactory results and you'll have to increase the link bandwidth. So as @Christian_R has suggested while I was working on the first edition of this comment :-), one of your solutions could be to aggregate several physical links between the switches (using LAG for example, if the switches support it) so that the inter-switch link capacity would be 2-3-4 times higher than the capacity of the individual servers' links.
Another workaround, already mentioned yesterday, was to reduce the bandwidth available to individual clients by throttling their respective ports to 100 Mbit/s.
Yet another workaround, much more efficient in mitigating the overbooking of the inter-switch link but much more unpleasant for clients than priority management by queueing, would be to obtain a safer ratio between the server links' bandwidths and the inter-switch links' bandwidth by throttling the servers' links down to 100 Mbit/s. The difference to the previous one is that this will not cause TCP retransmissions, for the same reason like if you raise the inter-switch links' bandwidth.
Thank you so much for the excellent analysis and insights. I truly appreciate it. The only other possible option I can think of to mitigate the problem would be to somehow limit the application on the server at the source. I have no idea if that is an option, but I will be asking those who manage the application to investigate as I can now say I have sufficient information and have considered all possible options within my scope.
I've clicked the little 'thumbs up' icon expecting that helps give praise. If there's some other way of marking this as 'answered' please let me know. I've found all the information here incredibly helpful.
Thank you.
There should be a grey checkmark (or star?) icon below the "thumbs down" icon below the large number next to each original Answer (i.e. not at comments to that Answer). If you open a question from the list whose number of answers is on a light green background, you'll see that checkmark in bright green at just one of the answers. This icon is only available to the user who has posted the Question so I don't remember how it looks like when inactive as I've posted my only question so far question in September, and its purpose is to indicate, to other people who came to ask a similar question, the answer which has proven to be most useful. Any user can press the "thumbs up" icon but doing so doesn't mark the question as answered (which is a common source of confusion but there is a purpose behind that behaviour).
These buttons at the answers raise or decrease (thumbs down) the karma of the user who has provided the answer (see site faq); the thumbs up icons at comments indicate the usefulness of the individual comments (and prefer them for display in "folded" mode) but don't affect karma.
But back to your issue, three more points not much related to each other:
I hope that the APs can split their own "overhead" (control/management) traffic and the user traffic passing through them into separate VLANs, or at least into different IP subnets, because you don't want to prioritize the complete traffic of the APs over the one of the wired connections.
it is not 100% clear to me from what you wrote whether there is just a single server in your network or more, but I guess there is at least some connection to the internet which I suspect to be something better than a 2 Mbit/s ADSL line since we talk about a campus here. So throttling just the single server you talk about, even if it can really be done at the server itself, may possibly only reduce the number of occurrences of the AP reboot issue. I mean, you should identify also other possible sources of high-bandwidth traffic before taking any active steps. Even client PCs may become sources of high-bandwidth traffic, depending on the applications you use. Several clients simultaneously copying large files to some network folders are the simplest example.
please investigate the eventual possibility of traffic shaping at the switches through X-on/X-off sent to the connected equipment. If it is available, it should allow smoother steps of source throttling than port speed (10/100/1000) settings.