I have a .pcap file which has packets of HTTP protocol, one of which has text/html written in the info column in Wireshark. When I double click this packet, I get a window showing the packet details, and there is a node Line-based text data. After this, the entire HTML payload is there.
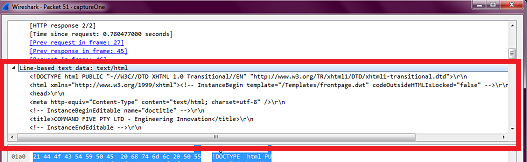
When I used tshark -r "path\to\pcap\file.pcap" -t ad > "path\for\text\file.txt" -V tshark command to convert the packet details from .pcap file to .txt file, I found the HTML payload (i.e. the entire page HTML):

I want to get this HTML payload using tshark. So I looked in the Display Filter Expressions window of Wireshark to find the field which would get me this HTML payload, and I found that the field is data-text-lines.
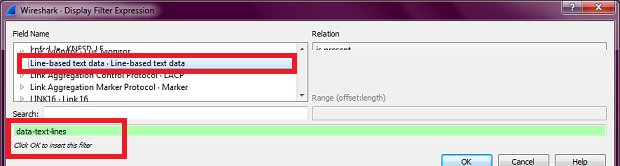
But when I used tshark -r path\to\pcap\file.pcap" -T fields -e "data-text-lines" > "path\for\txt\file.txt", all I got is one following line in the middle of otherwise empty file:
So what should I do? How do I extract the entire HTML of the page, which is very much there, but I am unable to extract it using some tshark field?
asked 20 Aug '16, 23:34

Jesss
51●14●17●20
accept rate: 0%

Thank you. I added
-E "occurrence=a"to the command, but the output is the same as that without the-Eargument. =(In that case, please upload the capture somewhere (cloudshark is preferred here but any plain file sharing service like google drive, dropbox, microsoft onedrive, ... will do) and edit your Question with a login-free link to it. Guessing by screenshots is a pain.
@sindy Can I do that while ensuring that I don't share my IP address. I am a lil concerned about sharing my IP or MAC address publicly...
Look at the anonymization features of Tracewrangler.
@sindy Tracewrangler has removed all my HTTP packets :s
Try again, but this time uncheck the
Remove all unknown layers and ...in the Payload menu which is on by default.Tracewrangler is a powerful tool, and these intrinsically tend to be dangerous.
@sindy Here: https://www.cloudshark.org/captures/234d85d617e2 Please apply a display filter, and then see the second packet (It has "text/html" written in info section)
Hm, so my assumption based on your screenshots was wrong, the "line-based text data" is a single item and shows size of 1045 bytes, but copying its value provides only the first line.
Worse than that for you, the http dissector could not determine that the text data in frames 10,11,13, and 14 should be handled together, so the payload in frame 10 is dissected as "line-based text data", and its individual lines are dissected into plain "text" fields, the payload in frames 11 and 13 is handled as just "data", for which an alternative representation "data.text" exists, and the payload in frame 14 is dissected as "xml". To make it even more complex, several other items in lower layers of these frames also generate "text" fields.
So all in all, an automated export of http payload from this mess is close to impossible.
@sindy Ooh.. so does that mean there is no way to extract HTTP payload from a
.pcapfile?In general it doesn't, but for this particular payload, the http dissector seems to have an issue with the reassembly. Normally, the last packet of the response (frame 14 in your example capture) would have another tab with a reassembly of the http response as a whole, but this one doesn't. I may only guess that the dissector cannot handle it properly e.g. because the server uses an old version of html and specifies the payload type as text/html.
@sindy "Normally, the last packet of the response (frame 14 in your example capture) would have another tab with a reassembly of the http response as a whole" - how would I extract the payload through tshark (commandline) if the reassembled http response WAS present there?
I haven't found any. The protocol dissectors normally dissect the data they can handle into individual items (= fields) but do not create a field with all the source data as a text or byte string. In GUI Wireshark,
File->Export Objects->HTTPcan be used, but no equivalent functionality is available in tshark.@sindy OK. Thank you so much for your help.