
The upload made from a client (win 7) has very poor performance. The same made from another client has acceptable performance. slow upload -> slow_session_anon.pcapng fast upload -> fast_session_anon.pcapng http://en.file-upload.net/download-12139835/captures.rar.html When I compared both files, i could see that the slow upload does not enter slow start phase. it constantly transfers at the same rate. Please comment on my thoughts and potential reason for such an issue. Thanks asked 03 Dec '16, 01:57 soochi showing 5 of 16 show 11 more comments |
2 Answers:
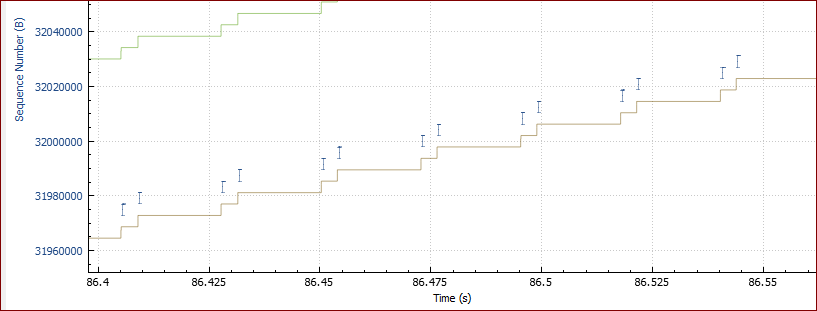
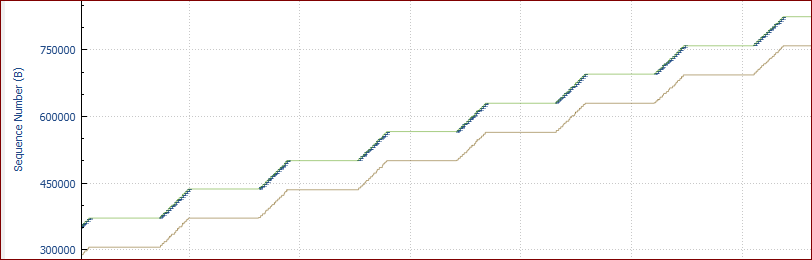
First some items that are the same (or close) in both captures: 3-way handshakes are the same, client supports windows scaling but server does not (or something in the middle doesn't). Therefore, the receive window can never be more than 64KB. Both support SACKs and both specify an MSS=1460. The server advertises a receive window of 64KB constantly in both cases (after a ramp-up very early on that closely matches the slow start). The 64KB is reached by ACK #101 in "fast" and ACK #103 in "slow". The minimum RTT is the same in both cases at just under 22ms (the "fast" example is a touch longer than the "slow"). There are several instances of packets arriving out-of-order at the receiver (but in the correct order when we see them). The amount of time they are OOO is just 1 microsecond. We can infer this by SACKs that originate from the receiver. I'll just give one example from each capture: "Slow": The first 1460 bytes of #47602 are overtaken downstream. One RTT later, SACKs #47613, #47614, #47615 announce a gap of 1460 then ACK #47616 (zero time after #47615) tells us that the 1460 byes arrived after all. That is not enough to stop the client sending #47617, a retransmission of the 1460 bytes, in response to the 3 x SACKs (equals 3 x Dup-ACKs). "Fast": Same story. Data in #33247 is overtaken, SACKs #33321, #33322, #33323 announce it, ACK #33324 acknowledges the missing 1460 but client data #33325 is sent as an unnecessary retransmission. These OOOs and retransmissions have very little or no effect on the overall throughput. The difference in throughputs is due to the different send buffer sizes. "Fast" maintains a consistent packets-in-flight of 64KB whereas "slow" maintains just 8KB. You could calculate 64KB per RTT vs 8KB per RTT (RTT=22ms) - or just say that "fast" has 8 times the throughput of "slow". Compare these snippets of Stream-TCP-Trace graphs - which are essentially the same for the whole periods. Note the vertical height of the bursts per RTT.
But what is the cause? In the "slow" example, we see one of those OOO cases very early, during the third burst in the slow start phase when we've only ramped up to 7KB per RT. This behaviour is not in the "fast" capture. Packet #30 is seen in the correct order in the capture - but is overtaken before it arrives at the receiver. This can be inferred by the SACKs #36 and #37 followed by ACK #38, all in the space of 2 microseconds. There is no data retransmission because we only got two SACKs (which are also treated as Dup-ACKs) - not the three required for a fast retransmission. With only one example of each, I can only guess why the client decides to keep its send buffer at just 8KB. It seems unlikely that the two SACKs are enough to "scare" it into the consistent reduced throughput for the whole duration? The timing of the OOO may be just unlucky. If the same PC is "slow" every single time, then it would seem more likely that some registry settings related to send buffer size are different. A quick Google gave me this (from "social.technet.microsoft.com/Forums"): Looks like afd.sys of windows 7 uses new registry key named HKLM\SYSTEM\CurrentControlSet\Services\AFD\Parameters\DynamicSendBufferDisable (DWORD). Setting it to zero forces winsock to use larger buffers. This is just one possibility. There may be a variety of other registry entries to find. There also may be other reasons for the small send buffer in this PC. Update: More Googling has revealed that this problem was well known. There are many web articles about this Windows 7 "flaw". A good one I found is from Feb 2009: (kb.pert.geant.net/PERTKB/WindowsOSSpecific) Buffers for TCP Send Windows Inquiry at Microsoft (thanks to Larry Dunn) has revealed that the default send window is 8KB and that there is no official support for configuring a system-wide default. However, the current Winsock implementation uses the following undocumented registry key for this purpose [HKEY_LOCAL_MACHINE\System\CurrentControlSet\Services\AFD\Parameters] Value Name: DefaultSendWindow Data Type: REG_DWORD (DWORD Value) Value Data: The window size in bytes. The maximum value is unknown. According to Microsoft, this parameter may not be supported in future Winsock releases. However, this parameter is confirmed to be working with Windows XP, Windows 2000, Windows Vista and even the Windows 7 Beta 1. This value needs to be manually adjusted (e.g., DrTCP can't do it), or the application needs to set it (e.g., iperf with '-l' option). It may be difficult to detect this as a bottleneck because the host will advertise large windows but will only have about 8.5KB of data in flight. Another useful one is: (www.htpcforums.com/index.php?showtopic=631) The problem was that I could download fine but my upload maxed out around 2 Mbps! It was 10x slower than it should have been. Then I learned about DefaultSendWindow and the fact that it isn't properly set on Vista machines but it is set in Windows XP, believe it or not. For a while I was wondering why my Windows XP laptop could do 10 Mbps up over WiFi while my wired desktop could only do 2 Mbps. In both cases, the DefaultSendWindow needed to be changed, here's how: 1) Regedit: HKLM\System\CurrentControlSet\Services\AFD\Parameters 2) If the DefaultSendWindow value is not in there, you will need to add it. Right-click on the right column and choose "New > DWORD Value (32-bit)" and name it DefaultSendWindow. Make sure that you enter it exactly like that, with the first letter of each word capitalized. Note from PhilSt: Section 3 about calculating values snipped. We need 65536 here (0x10000). 4) Once you have the value, double-click the DefaultSendWindow value and make sure the "Base" part is on Decimal. Enter the number you got from the formula above into the value field, then put the radio button on "Hexadecimal" and click OK. The value needs to be in hexadecimal format for it to work right, but it is easier to calculate the optimal value in decimal format so that is why I said to enter it in decimal then change it to hex before saving. 4) Restart your system answered 07 Dec '16, 01:22 Philst edited 08 Dec '16, 16:41 The application send buffer was not properly implemented. This the cause of the issue. DefaultSendWindow as a workaround solved the issue. i tried out various values for the send buffer and finally choose 64K as the optimum value. The programmer is informed of this issue. Thanks Philst good catch :) (10 Dec '16, 03:18) soochi Well I think the solution you have found is a good one. But just out of curiosity have you ever found out why the fast client is the faster one? (10 Dec '16, 10:19) Christian_R 2 because of the registry entry (DefaultSendWindow). This entry came into place on the faster computer due to installation of Citrix client software. I made several verification to make sure that the Jave software is not implemented properly: 1, Used the non Java based version of the software to do the upload. With Internet explorer 49K of bytes in flight achieved. Firefox could send up to the server window size (64K), there were many events of window full condition. 2, Removed the DefaultSendWindow setting from fast computer which then could only send to a maximum bytes in fly of 8K. Configured this setting on slower computer which improved performance. as per my tests, this setting does increase/decrease the Bytes in Flight in the case when the software is not programmed to provide "send buffer". (11 Dec '16, 02:22) soochi Yes that explaines a lot of things. And than this solution is really your root cause solution. (11 Dec '16, 02:41) Christian_R But one last question have you manipulated the autotuning values at win7 before? (11 Dec '16, 11:51) Christian_R which exact values do u mean? (12 Dec '16, 12:33) soochi something like this: netsh interface tcp show global (12 Dec '16, 12:42) Christian_R no changes were made from the default config other than the software installation changed the default send buffer, which i did not see in any netsh output. (12 Dec '16, 14:02) soochi I'm glad to know that you have verified the answer and implemented a "fix". There is room for even more improvement. Have another look at the "fast" chart above. There are still sizable "pauses" in the flow - waiting for each 64KB chunk to traverse the network and be ACKed. If you send even more packets per round trip, you'd get even higher throughput. With 128KB per RTT, you'd double throughput and halve the time. To achieve this you need to enable TCP Window scaling (at both ends) - as well as set a larger DefaultSendWindow value. (13 Dec '16, 17:39) Philst showing 5 of 9 show 4 more comments |
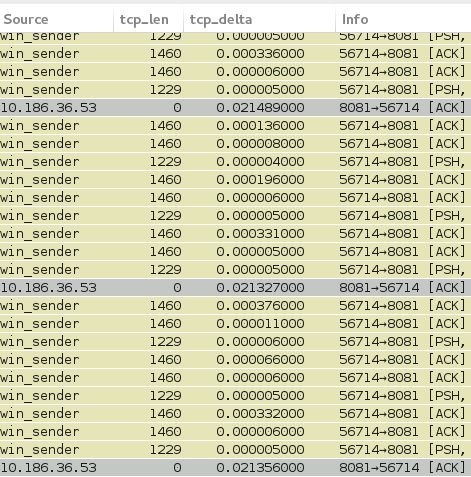
This might be a problem with the Nagle algorithm enabled at the sender and the dataflow flow involving an odd number of segments with the last one being a non-full-MSS . Regards Matthias Why do I think that Nagle is in place and the session is waiting for an acknowledgement ? If you apply the filter And odd numbers of segments in a row with the last one being less than one MSS rings a bell ... Regards Matthias answered 04 Dec '16, 06:46 mrEEde edited 04 Dec '16, 13:31 Both the clients should have the same configurations. Can you please explain me the reason of thinking why Nagle is in place? Can that be seen in the trace or is it a just guess? (04 Dec '16, 12:28) soochi I think that i get your point. Basically disabling Nagle should resolve the issue at least by half and the rest half by disabling Delayed ACK at receiver. let me describe for my clarification and understanding :) 1, When disabling Nagle at sender, the sender TCP will not wait for the application to send enough data to fill the MSS. 2, But if the application send only 7 blocks of data to Sending TCP and due to Delayed ACK implementation at the receiver side, this seventh segment can only be acknowledged once the timer expires :( 3, At this same time the Sending application can only send data to TCP after receiving acknowledgment for the seventh segment :( so to speed up the process delayed ack must also be disabled at receiver. Did I get your point? Thanks (06 Dec '16, 13:16) soochi The receiver is - luckily - not delaying acknowledgements. (06 Dec '16, 14:50) mrEEde The Nagle algorithm does not come into effect here. Because the sender sends a non full MSS segment with PSH bit set even if the bytes in flight is non zero. There is more gap between the segments with full MSS comparing to non full MSS (11 Dec '16, 08:35) soochi |
Could you please try google drive cloudshark or dropbox. Can´ find the correct download link at the site. If I press download I should download a really strange executable. Which I will not do.
https://drive.google.com/file/d/0B7Io9WiIN49VU3F2Z1VKbUwxVVk/view?usp=sharing
For me at the first view the traces loks more or less similar. From my point of view: At least 1 of the next points is needed here for more detailed analysis. 1. The packets are truncated to 60 Bytes so the SMB part is missing. 2. Both traces are local traces with segementation offload enabled, so we can´ see what happens at the wire.
Either you disable segemntation offload during capture -> But it is also only a workaround. Or you try to capture as close as possible outside to that machine. Maybe with TAPs or SPAN ports.
The payload after TCP is encrypted, so only until TCP could be interpreted. Yes both captures are made at the end hosts which has offloaded segmentation to NIC.
But still analysis must be possible because: 1, both traces are identical until frame number 29 (which ACKs frame 25) 2, the slow transfer total duration until this point is 229ms and fast transfer is 240ms
There is something which causes the slow transfer to always send segments of 4133 and 37 bytes (stays constantly). what could be the cause for that? considering both the transfers uses the same network path and same network conditions what could be the reason for such a packet pattern.
What could cause an application to send data in such a fashion.
Yes you are right with the application layer. I have thought we talk about smb, but seems that mixed it wit an other question here. I will have a deeper looker today.
First of all you are right, the fast transfer is 10 times faster, than the slower. But with this tcp segemtation offloading the root cause is still hard to find.
It seems that the client app does send the data to the stack in a slower way, than in the fast example.
Thanks for your effort :) and you too are right regarding offloading. This is the capture which i got from the client. I will try to get a better capture from somewhere in the transit path as near as possible to the client.
But for the mean time do you find anything like TCP stack not functioning properly?
it seems to me that the TCP stack is handled data to .....
just got a mail that u worte the same :)
This is also what I think that the TCP stack is starving for data. But interestingly in the following combination the transfer is fast.
client -> sends data to proxy (to reach proxy the latency is less than 1ms). In this constellation the transfer is fast.
I do accept that these are two different TCP connections, the one from client to server via proxy and the one direct. They do not have anything to do with each other. But in fact the slow client performs well when it connects via proxy.
because of this, i doubt if the capture from the wire would help. Have you heard of any reason for this particular situation: client app does not send data to TCP because it somehow detects that its connected via a high latency link. to be specific the client took 404us at frame 34 to send data and in fast transfer the same took just 71us and has larger amount of data.
I could manage the same transfer after disabling offloading https://drive.google.com/file/d/0B7Io9WiIN49VWHp3SHZoYkR6UkU/view?usp=sharing
Seems the problem is gone now?! The session lives now for 24 sec. like the fast one in the prevs captures! Maybe the system has problems with offloading?! If thats the case I would recommend to update the nic drivers at first.
:) no the problem exists. The transfer is only around 11 MB instead of ~70MB from the previous captures.
I have the following observation:
As you also told before the application does not feed TCP with data but under which circumstances does this happen... it seems to me like that when once the bytes in fly are reaching nearly the receive window, the slow stop phase stops.
to be specific at frame 45 this happens and after that the pattern of 9 frames persists consistently (slow_session.offdis_anon.pcapng).
just my thoughts please comment.
The question to me is: Is the fast client always fast and the slow client is always slow? If the answer is yes you could do the following things:
Try a tool like crwinnetdiag to examine the differnet configurations of the clients
You can follow the answer of @mrEEde
If the answer is no:
The problem is inside the client aplication.
I will verify/double check if both the clients have the same config.
ultimately my goal is to explain this strange behavior. There must be some factor triggering this condition. What do you think of my previous comments?
I suggest you to examine both clients with crwinnetdiag, because it parses the relevant Registry settings and it should be easy to find the differences with that tool.
And it also parses the AFD Registry settings.