
Here is my setup - I have one sender, one receiver and one monitor (in between the sender and the receiver - acting as a router ) - the sender and receiver communicate through the monitor. However, when I measure the throughput at both ends, i am not able to utilize the whole maximum bandwidth (capacity) available. For example, withe the given bandwidth,delay and loss - we normally expect our throughput to be around 250mbit/s or above. However, I am getting about 124mbits/s at both ends and i don't think this is realistic both theoretically and practically. How can we maximize the maximum capacity when we turn the segmentation OFF? I would be so much grateful if you could give me some hints on this. asked 09 Apr '17, 12:45 armodes edited 10 Apr '17, 18:00 showing 5 of 10 show 5 more comments |
2 Answers:
I might be wrong but I'm guessing both sender and receiver are running Linux with CONFIG_HZ=250 in a Virtual Box environment. My suggestions to get a better throughput would be to Regards Matthias answered 09 Apr '17, 22:50 mrEEde OK i will do that Matthias but the reason why I have MTU size as 1500 is because i turned the TCP segmentation offload OFF. (10 Apr '17, 00:45) armodes If this is all a virtual environment and you are not going out via real ethernet cards , there is not much benefit in saving the CPU cycles at the sender just to have them burned in the host's operating syxstem. It won't make things faster. (10 Apr '17, 00:55) mrEEde The main purpose of offloading segmentation is to save CPU cycles at the sender by having the ethernet card do this. From a performance perspective it is always best to send data in as large segments as possible. So with 1500 MTU you need to send roughly 6 times more packets than with 9000 which puts unnecessary load on the host and on the receiver. . if you are CPU constrained already in this situation - which is what I think is limiting performanec here - both enabling segmentation offload and using MTU 1500 is detrimental to gaining good performance. (10 Apr '17, 08:16) mrEEde |
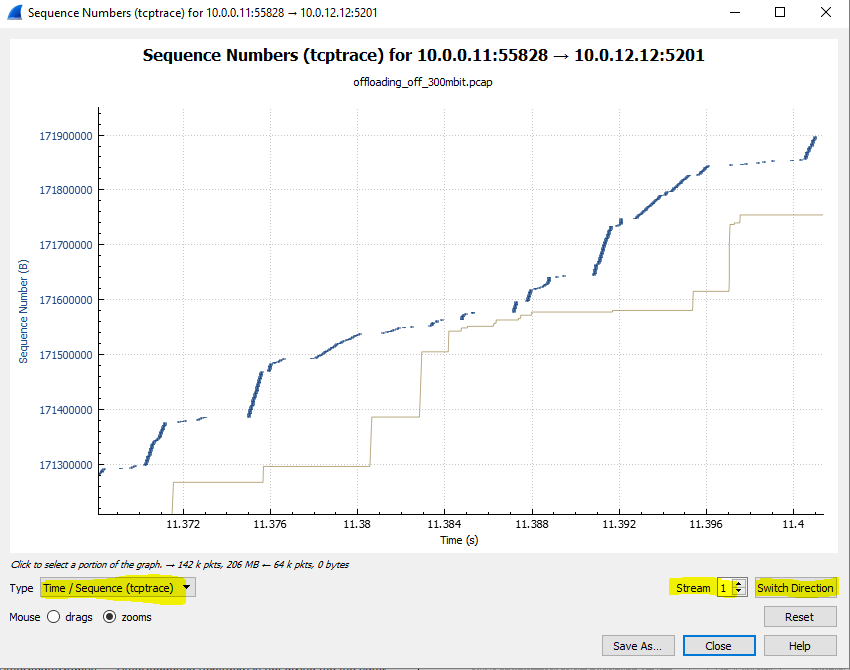
The throughput limitation here appears to be due to the sending client. The server almost constantly advertises a Receive Window of 1.5 MB but the client seems to transmit sometimes in fast bursts (but never filling the 1.5 MB window) but mostly at a slow rate. The Transmit Window never gets above 200-300 KB. This means that Window Scaling is being used - so we can eliminate the 64 KB per round trip limitation. Some of this does seem related to transmit window "halving" in response to packet losses, but even without losses, we get a transmitted flow as in the attached TCP Stream diagram. There are far more "slow" transmissions than "fast" bursts.
Notice also that the horizontal distance from the data packets to the ACK line indicate varying RTTs. They range from 3 ms to 13 ms. Actually, looking more deeply, this is due to there being large time gaps between the server's ACKs. There isn't the usual ACK for every two packets. I'd say that the server's ACKs have been dropped by the sniffer (given that there are lots of missing data packets in this trace file that were also dropped by the capture mechanism). It would seem to me that there is no TCP level reason for the slow transmit rate. You need to be looking at your client and why it would slow its output in this way. That is, could there be an application layer bottleneck? answered 10 Apr '17, 02:07 Philst edited 10 Apr '17, 17:04 The reason why we get window halving due to the TCP variant i am using (CUBIC). I can't understand why the sending client is behaving that way. Turning the window scaling is also not a good option :( How can i reproduce that graph by the way? Statistics -> TimeSteamGraphs -> TimeSequence (tcptrace) is not giving me the same graph. (10 Apr '17, 04:43) armodes 1 I've changed the diagram so that it now contains the Wireshark settings. You have to choose the correct "Stream" and you may also have to "Switch Direction" in order to see the client's packets. Window Scaling is enabled, so no tuning needed. The "halving" is normal TCP "Congestion Avoidance" behaviour. The throughput rate appears to be the "fault" of the sending application rather than anything at the TCP/IP or network level. The reason that the sending client is behaving this way is not apparent from the capture. You're going to have to do some different analysis inside your virtual machine and/or application. Is there a buffer limitation for the application to deliver data to TCP? Those slow output rates, such as at time 11:38 on the chart, are because the sender is choosing to do that, not because of any network or TCP/IP limitation. (10 Apr '17, 17:12) Philst |
Maybe it's the segmentation that is required to achieve maximum speed - I mean, it's a performance feature, so it's not that surprising that you don't reach max speeds without it...
Where do capture, inside or outside the offloading machines? From my point of view an internal capture is by far not trustworthy.
I agree with @Christian_R - when you're investigating issues like this you should go at least for a SPAN port capture. Better would be a full duplex capture using a TAP and a high precision capture card, of course, but that's expensive.
@christian_r, i am turning the offloading OFF on both the sender, receiver and the monitor.
You can do this. But then you have manipulated the whole network setup. So best thing is to trace external. If you can't do then disabling offloading maybe a workaround. Can share us the trace? BTW in your example it looks like you have disabled offloading. How did you generate the traffic?
@christian_r, yes I have disabled offloading and I am generating the traffic using iperf and capturing the traffic on the monitor (between the sender and the receiver)
O.k. Do you generate UDP or TCP traffic?
@christian_r, i have tried it with both TCP and UDP. Here is my trace file:
https://drive.google.com/drive/folders/0B4Ajk8jGD1OxbS15amlQZGVFTk0?usp=sharing
OK: And in TCP and UDP you got the results?
@christian_r, yes but the problem is the maximum bandwidth utilization is the same with both TCP and UDP.